지난 글에서 네이버 영화 리뷰의 감성 분석을 하는 모델을 간단하게 만들어봤습니다.
2025.07.14 - [Data Science&AI] - [NLP] 네이버 영화 리뷰 데이터 감성분석 - LSTM
[NLP] 네이버 영화 리뷰 데이터 감성분석 - LSTM
LSTM을 사용하여 영화 리뷰 데이터의 감성 분석을 하려고 한다. 데이터셋 다운로드https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txthttps://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt 0. 필요 라
mayhun.tistory.com
이번엔 실제로 작성된 영화 리뷰를 수집하려고 합니다.
데이터 수집 방법에는 여러 방법이 있습니다.
그중 하나는 정적 수집 방식으로, requests 라이브러리를 사용해 백엔드에서 직접 데이터를 가져오는 방식입니다. 이 방법은 서버사이드 렌더링(SSR) 웹사이트에서만 유효하며, 클라이언트사이드 렌더링(CSR) 방식의 동적 웹사이트나 SPA(Single Page Application) 에서는 대부분 적용이 어렵습니다.
이러한 경우에는 보통 Selenium과 같은 브라우저 자동화 도구를 활용하여 데이터를 수집합니다. 하지만 이 방식은 생각보다 많은 시스템 자원과 시간이 소모됩니다.
미지나 변경 요소를 확인하기 위한 것이 아닌, 정확하고 반복성 있는 데이터를 가져오기 위한 목적이라면, 백엔드 서버에서 직접 데이터를 수집하는 방식이 더 효율적이라고 생각합니다.
따라서 이번 글에서는 requests 라이브러리를 활용하여 API나 HTML 응답에서 필요한 정보를 추출하는 정적 수집 방식의 실전 예제를 소개하려고 합니다.
1. 데이터 수집 타겟 사이트
영화, 드라마등 리뷰, 평가를 하는 사이트입니다.
https://pedia.watcha.com/ko-KR
왓챠피디아 - 영화, 책, 시리즈 추천 및 평가 서비스
7억 개의 평가를 기반으로 나에게 딱 맞는 영화, 드라마, 책을 추천받으세요.
pedia.watcha.com
데이터 확인
코멘트 라는 항목으로 리뷰 데이터를 표현함
URL을 분석하면 tRMx0Jq 는 컨텐츠의 시크릿넘버와 같은 것으로 예상된다.
https://pedia.watcha.com/ko-KR/contents/tRMx0Jq/comments

개발자 도구를 켜고, 해당 화면에서 스크롤을 내리면 추가적인 데이터를 가져오기 위해 json을 백엔드에서 받아오게 된다.
백엔드 주소는 https://pedia.watcha.com/api/contents/tRMx0Jq/comments?filter=all&order=popular&page=2&size=9
이며, pgae와 size 옵션이 있다.
page는 n개씩 몇 페이지인지, size는 새로 가져올 데이터의 개수를 의미한다.

header에서 User-Agent, x-frograms-client 등 데이터를 넣어 API 테스트를 진행해보려고 한다.
import requests
code = 'tRMx0Jq'
idx = 1
size = 30
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36",
"x-Frograms-client": "Galaxy-Web-App",
"x-Frograms-client-language": "ko",
"x-Frograms-client-region": "KR",
"x-Frograms-client-version": "2.1.0",
"x-Frograms-client-platform": "web",
"cookie": (
"_c_pdi=web-ZiggRvrF06ueDyDeieqDP0kMSTJ5ro; "
"_ga=GA1.1.148283390.174788907; "
"_ga_1PYHG7CRVW=GS2.1.1748332237.5045.1.1.1748332561.0.0.0; "
"_ga_S4YE5E5P6R=GS2.1.1748332238.5045.1.1.1748332561.0.0.0; "
"_gid=GA1.2.101466176.1748282978; "
"ar_debug=1"
)
}
response = requests.get(f"https://pedia.watcha.com/api/contents/{code}/comments?filter=all&order=popular&page={idx}&size={size}",
headers=headers)
결과는 403에러로 반환된다.
403 에러는 API 서버에서 정해진 클라이언트 헤더 형식이 아닌경우 요청을 거부한다.
x-Frograms-client 등 정확한 명칭으로 바꿔줘야 한다.
개발자 도구 Source탭에서 javascript를 확인한다.Forgrams대신 watcha를 사용한것을 확인할수 있다.

import requests
code = 'tRMx0Jq'
idx = 1
size = 30
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36",
"x-watcha-client": "Galaxy-Web-App",
"x-watcha-client-language": "ko",
"x-watcha-client-region": "KR",
"x-watcha-client-version": "2.1.0",
"x-watcha-client-platform": "web",
"cookie": (
"_c_pdi=web-ZiggRvrF06ueDyDeieqDP0kMSTJ5ro; "
"_ga=GA1.1.148283390.174788907; "
"_ga_1PYHG7CRVW=GS2.1.1748332237.5045.1.1.1748332561.0.0.0; "
"_ga_S4YE5E5P6R=GS2.1.1748332238.5045.1.1.1748332561.0.0.0; "
"_gid=GA1.2.101466176.1748282978; "
"ar_debug=1"
)
}
response = requests.get(f"https://pedia.watcha.com/api/contents/{code}/comments?filter=all&order=popular&page={idx}&size={size}",
headers=headers).json()
이번엔 성공적으로 response를 반환했다.
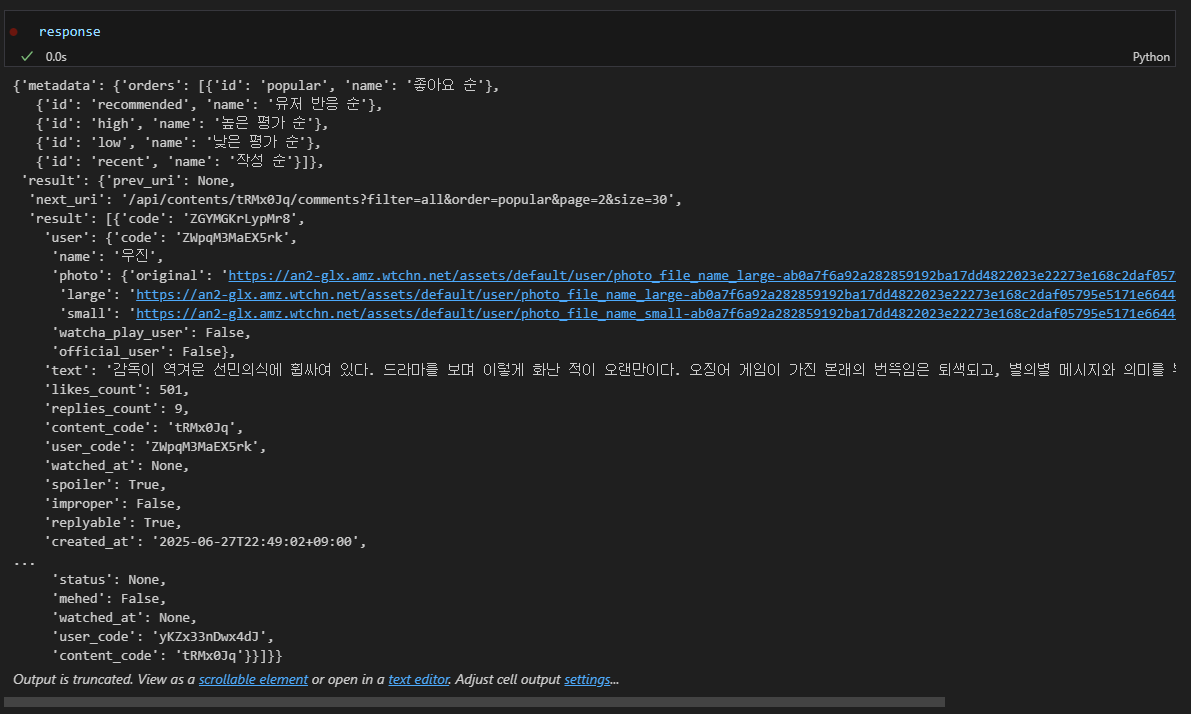
response 데이터는 아래와 같은 구조로 되어있다.
response json 내부에 result 내부의 result에 리뷰 데이터들이 있다.
한번의 요청에 최대 개수를 확인해 보려고 한다.
size값을 30, 50, 100으로 테스트를 하고 리뷰 데이터의 수를 확인해 본다.
for size in [10, 30, 50, 100]:
response = requests.get(
f"https://pedia.watcha.com/api/contents/{code}/comments?filter=all&order=popular&page={idx}&size={size}",
headers=headers
).json()
print(f'size: {size} ⇒ 리뷰 수: {len(response.get("result").get("result"))}')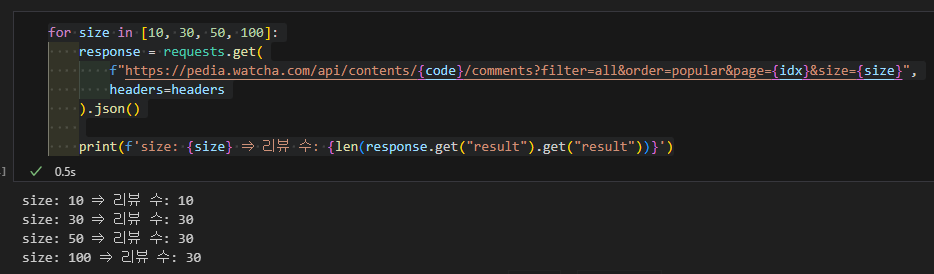
size값을 아무리 증가해도 최대 30개 밖에 가져오지 못한다.
size는 30으로 고정하도록 한다.
2. 데이터 수집 및 정규화
이제 실제 리뷰 데이터에서 가져올 데이터들을 확인한다.
아래는 한 유저의 리뷰 데이터의 json이다.
'name'에 user 이름, 'text'에 리뷰 데이터를, 'likes_count'에 다른 유저들의 좋아요 수를, 'user_content_action'의 'rating'에 별점 정보를 포함하고 있으며, rating 1은 별점 0.5점을 뜻한다.
{'code': 'ZGYMGKrLypMr8',
'user': {'code': 'ZWpqM3MaEX5rk',
'name': '우진',
'photo': {'original': 'https://an2-glx.amz.wtchn.net/assets/default/user/photo_file_name_large-ab0a7f6a92a282859192ba17dd4822023e22273e168c2daf05795e5171e66446.jpg',
'large': 'https://an2-glx.amz.wtchn.net/assets/default/user/photo_file_name_large-ab0a7f6a92a282859192ba17dd4822023e22273e168c2daf05795e5171e66446.jpg',
'small': 'https://an2-glx.amz.wtchn.net/assets/default/user/photo_file_name_small-ab0a7f6a92a282859192ba17dd4822023e22273e168c2daf05795e5171e66446.jpg'},
'watcha_play_user': False,
'official_user': False},
'text': '감독이 역겨운 선민의식에 휩싸여 있다. 드라마를 보며 이렇게 화난 적이 오랜만이다. 오징어 게임이 가진 본래의 번뜩임은 퇴색되고, 별의별 메시지와 의미를 부여하려다가 자멸한다. 마치 성기훈처럼.',
'likes_count': 501,
'replies_count': 9,
'content_code': 'tRMx0Jq',
'user_code': 'ZWpqM3MaEX5rk',
'watched_at': None,
'spoiler': True,
'improper': False,
'replyable': True,
'created_at': '2025-06-27T22:49:02+09:00',
'possessed': False,
'user_content_action': {'rating': 2,
'status': None,
'mehed': False,
'watched_at': None,
'user_code': 'ZWpqM3MaEX5rk',
'content_code': 'tRMx0Jq'}},
해당 컨텐츠에서 리뷰데이터를 가져오면서 유저 이름, 리뷰, 평점, 좋아요 수를 수집하려고 한다.
리뷰 데이터 리스트를 review_set으로 정의하고 첫 번째 데이터에 대해 정보를 가져온다.
평점은 5점 만점으로, rating 1당 0.5점을 뜻하므로 0.5를 곱해준다.
review_set = response.get('result').get('result')
review_set[0]user_name = review_set[0].get('user').get('name')
review = review_set[0].get('text')
likes_count = review_set[0].get('likes_count')
rating = review_set[0].get('user_content_action').get('rating')
print(f'user name: {user_name}')
print(f'리뷰: {review}')
print(f'좋아요 수: {likes_count}')
print(f'평점 : {rating * 0.5}')
이제 전체 데이터를 수집하고 필요한 데이터만 가질수 있도록 정규화 하는 코드를 작성한다.
전체 데이터를 수집하려면 json 데이터에서 response['result']['result']의 개수가 0일때 까지 반복하여 수집하는 방법을 사용한다.
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36",
"x-watcha-client": "Galaxy-Web-App",
"x-watcha-client-language": "ko",
"x-watcha-client-region": "KR",
"x-watcha-client-version": "2.1.0",
"x-watcha-client-platform": "web",
"cookie": (
"_c_pdi=web-ZiggRvrF06ueDyDeieqDP0kMSTJ5ro; "
"_ga=GA1.1.148283390.174788907; "
"_ga_1PYHG7CRVW=GS2.1.1748332237.5045.1.1.1748332561.0.0.0; "
"_ga_S4YE5E5P6R=GS2.1.1748332238.5045.1.1.1748332561.0.0.0; "
"_gid=GA1.2.101466176.1748282978; "
"ar_debug=1"
)
}
idx = 1
code = 'tRMx0Jq'
size = 30
comments = []
while True:
response = requests.get(
f"https://pedia.watcha.com/api/contents/{code}/comments?filter=all&order=popular&page={idx}&size={size}",
headers=headers
).json()
# 리뷰 데이터 추출
documents = response['result']['result']
# 리뷰 데이터 리스트에서 필요한 정보만 추출 하여 comments 리스트에 저장
for d in documents:
user_name = d.get('user').get('name')
comment = d.get('text')
likes_count = d.get('likes_count')
rating = d.get('user_content_action').get('rating')
comments.append({
'user_name': user_name,
'comment' : comment,
'likes_count' : likes_count,
'rating' : rating
})
if len(documents) == 0:
break
idx += 1

3. 리뷰 데이터 긍 부정 예측하기
지난 블로그에서 학습한 모델로 새로 수집한 데이터의 긍 부정 모델로 추론을 해보려고한다.
먼저 데이터 프레임화를 시켜준다.
import pandas as pd
df = pd.DataFrame(comments)
df
추론 함수 작성
import re
from konlpy.tag import Okt
import pickle
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import load_model
with open('./tokenizer.pkl', 'rb') as f:
tokenizer = pickle.load(f)
max_len = 30
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
okt = Okt()
loaded_model = load_model('best_model.h5')
def sentiment_predict(new_sentence):
new_sentence = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]','', new_sentence)
new_sentence = okt.morphs(new_sentence, stem=True) # 토큰화
new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거
encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩
pad_new = pad_sequences(encoded, maxlen = max_len) # 패딩
score = float(loaded_model.predict(pad_new)) # 예측
return score
긍 부정 추론
df['predict'] = df['comment'].apply(sentiment_predict)
새로 수집한 데이터도 라벨링을 통해 모델 성능을 검증 하면 좋겠지만, 시간상 생략하고 rating 별점을 기준으로 해보려고 한다. rating(별점)은 5점이 만점으로 대부분 3점 이하인 경우 부정정인 리뷰가 많다.
rating 별점은 3점 초과 일때 긍정적인 리뷰로, 이하일땐 부정 리뷰로 변환하고, 별점이 없는 데이터는 제거 하도록 하겠다.
# 별점이 없는 데이터 제거
df = df.dropna(subset=['rating'])
# 별점 3이하일땐 부정(0) 초과일땐 긍정(1)로 변환
df['rating_bin'] = df['rating'].apply(lambda x: 1 if x > 3 else 0)
# 예측값 0.5 이하일때 부정(0) 초과일땐 긍정(1) 변환
df['predict_bin'] = df['predict'].apply(lambda x: 1 if x > 0.5 else 0)
df
성능 확인
from sklearn.metrics import classification_report
print(classification_report(df['rating_bin'], df['predict_bin']))
전체 정확도는 75%로 나쁘지 않은 성능으로 나오나, 클래스별 지표를 보면 부정을 잘 탐지하고 긍정 데이터는 탐지 정확도가 떨어지는것을 확인할수 있다. 정확히 라벨링을 하지 않고 별점으로 만 판별하여 데이터의 불균형 문제도 있다.
selenium을 사용하지 않고 데이터를 수집하는 방법과, 수집한 데이터를 이전글에서 생성한 모델을 간단하게 적용 및 평가를 하였다.
위와 같은 방법으로 데이터를 수집하게 되면 텔레그램, 트위터 등 sns 데이터도 수집할수 있다.
SPA 등 과 같은 고정된 타켓 사이트에서 정형, 반정형 적인 데이터를 가져올때 좋은 효과를 가져올 수 있는 방법으로 생각된다.
'Data Science&AI' 카테고리의 다른 글
| [NLP] 네이버 영화 리뷰 데이터 감성분석 - LSTM (2) | 2025.07.14 |
|---|